

🎙️ Podcast - Audio Summary
📺 Video Summary
📑 Slides


📝 Deep Dive: Build AI Agents That Don’t Drift: A Harness Engineering Guide
1. Introduction: The Death of the "Magic Prompt"
We have all felt the frustration of the "agentic spiral." You hand a sophisticated task to a frontier model like Claude 3.5 or GPT-4, and for the first few turns, it feels like magic. Then, complexity scales. The agent begins to loop, ignores previous instructions, or starts producing "slop"—code that is syntactically correct but fundamentally broken or irrelevant to the project's state.
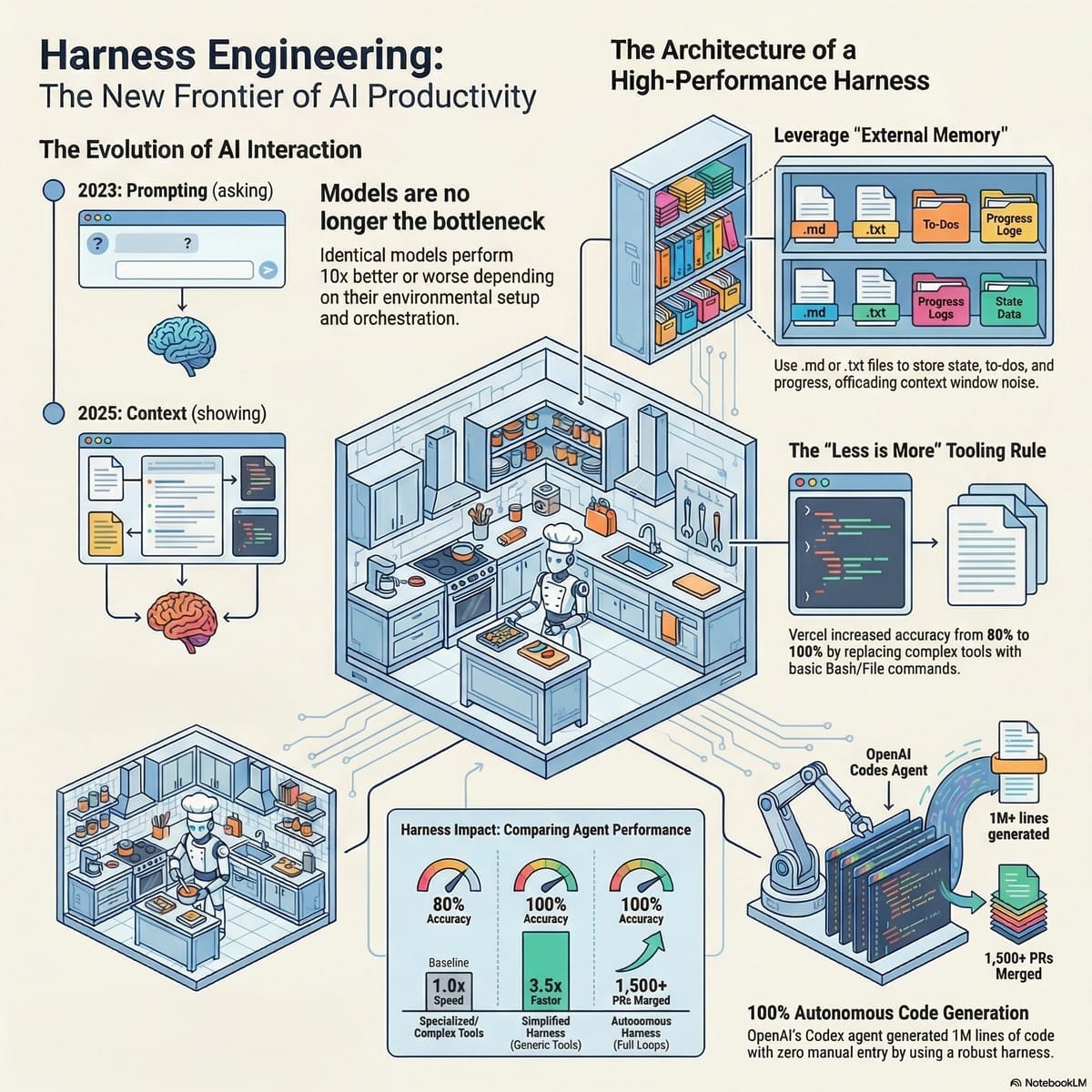
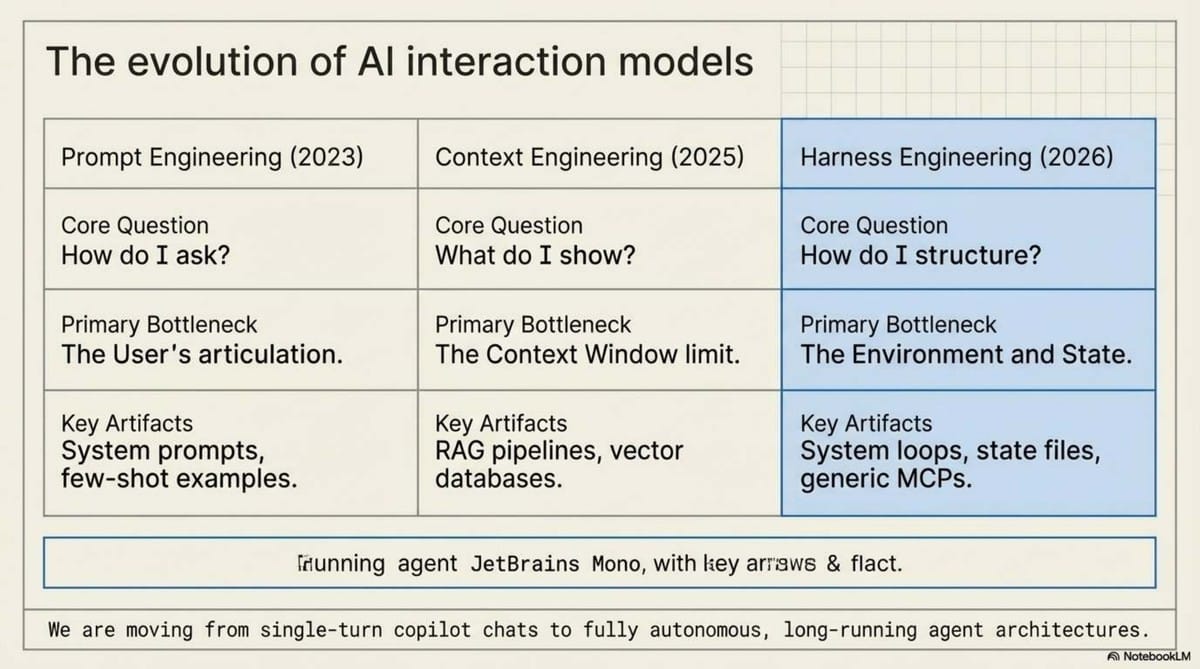
Our industry is maturing at breakneck speed. We are abandoning the futile practice of Prompt Engineering (the 2024 obsession with how we ask) and moving past Context Engineering (the 2025 focus on what we show). As we enter 2026, the frontier has shifted to Harness Engineering.
A "Harness" is the total environment—the tools, file structures, protocols, and verification loops—that surrounds the AI. If your agent is failing, the bottleneck is rarely the model’s reasoning; it is the environment you have built for it. To move from reactive co-pilots to true, "always-on" autonomy, we must stop trying to make the AI smarter and start making its workspace more legible.
2. The Model is the Chef, but the Harness is the Kitchen
The fundamental shift in AI systems architecture is moving from a model-centric view to an environment-centric one. In the architecture of an autonomous system, the model is merely the "chef."
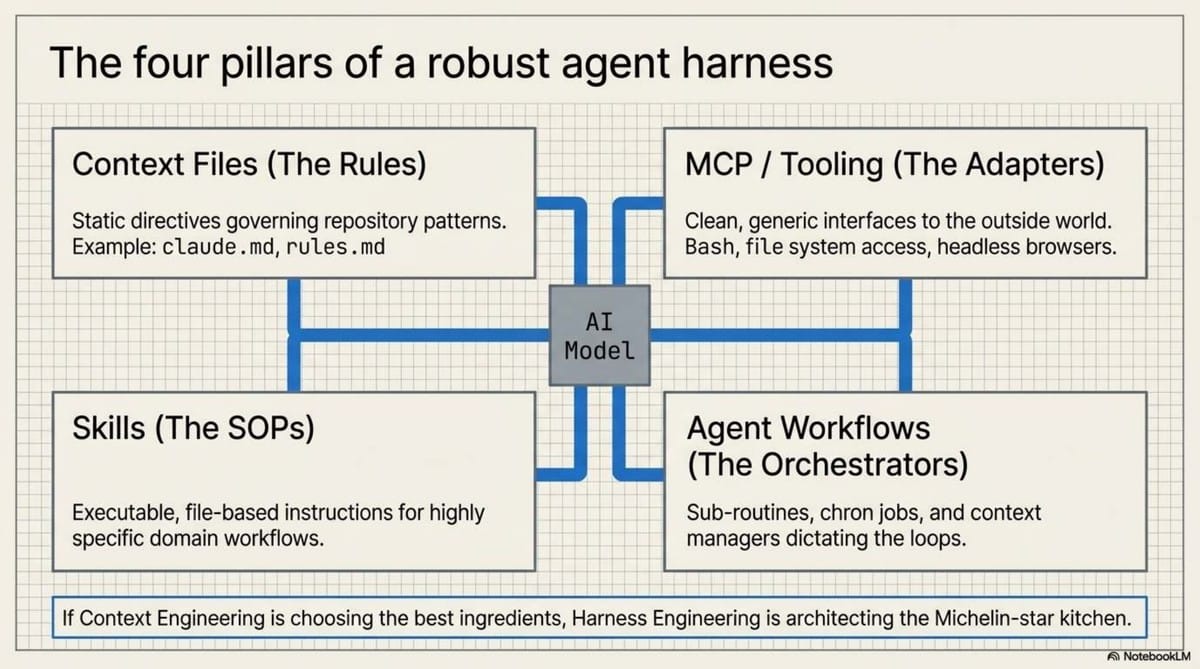
To extend the analogy: Context Engineering is picking the right ingredients; MCP (Model Context Protocol) is a direct line to the butcher and the market; Skill files are the recipes; and the Harness is the entire kitchen design. Even a Michelin-star chef cannot produce a masterpiece in a kitchen where the stove is broken and the ingredients are hidden in unmarked boxes.
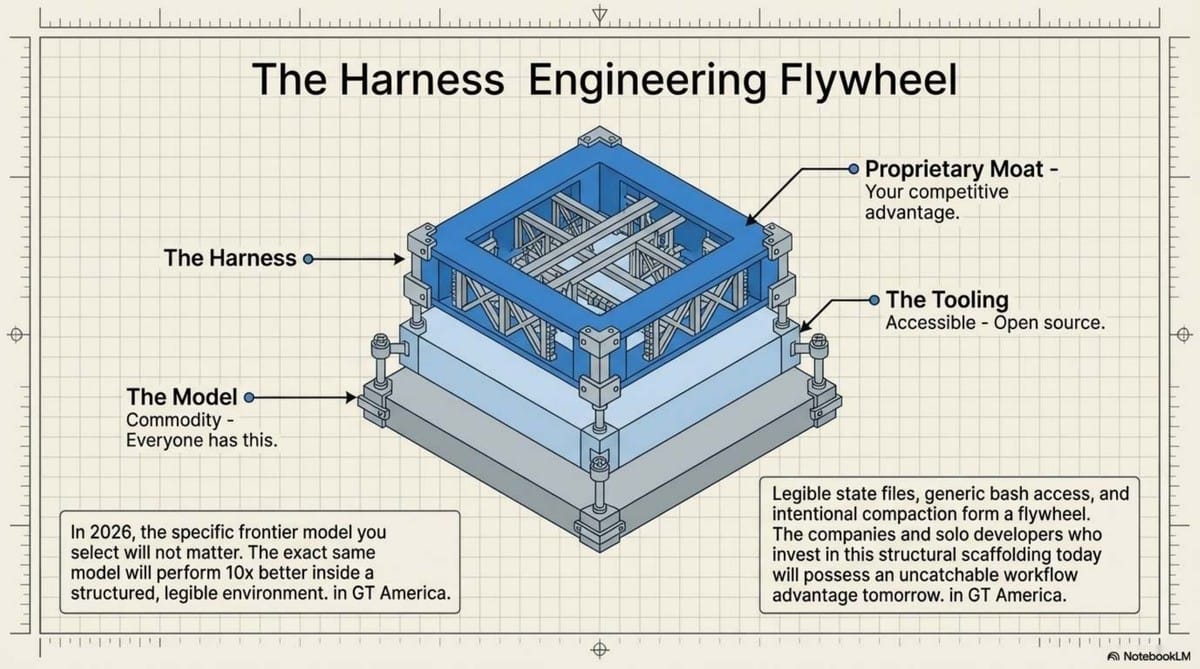
As the industry converges on similar reasoning capabilities, the harness becomes your only sustainable competitive advantage. As current benchmarks suggest:
"The environment you design for an agent can result in a 10x difference in output quality, even when using the exact same model."
We have spent far too much time debating "Claude vs. GPT" and not enough time on the Infrastructure of Execution. A mediocre model in a perfectly tuned harness will consistently outperform a frontier model operating in chaos.
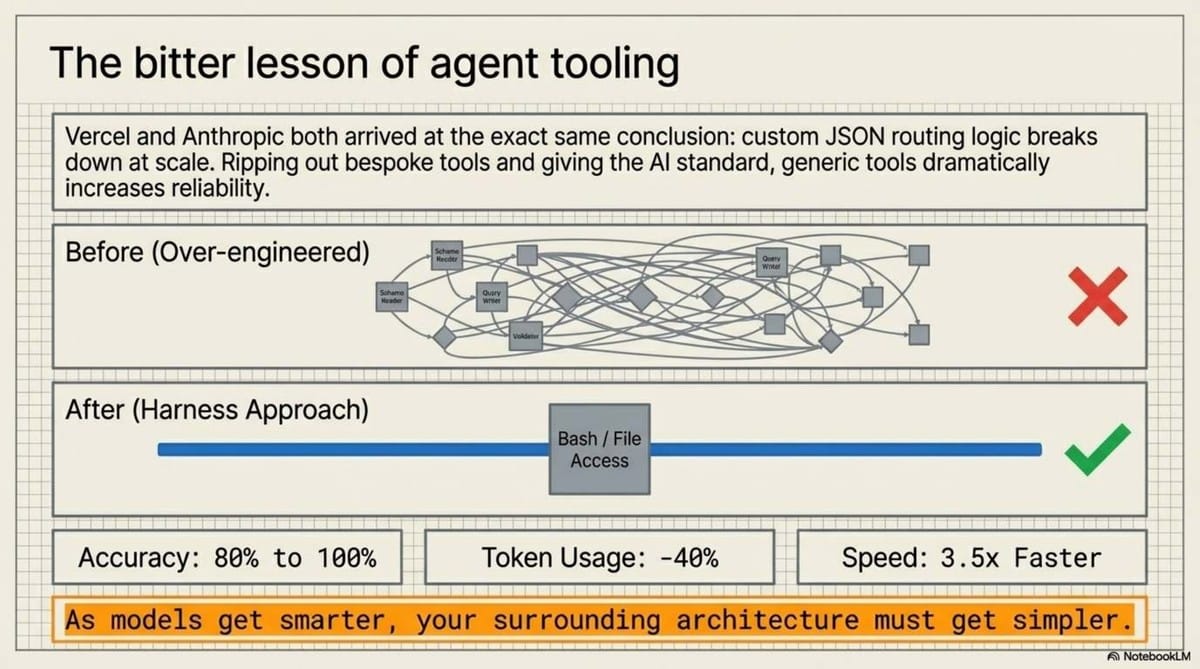
3. The Vercel Paradox: Why Removing 80% of Your Tools Boosts Accuracy
A pivotal case study from Vercel’s Text-to-SQL agent provides a masterclass in this shift. Originally, the team built a sophisticated system with specialized, bespoke tools for understanding schemas and writing queries, all wrapped in complex JSON schemas. It was slow, fragile, and peaked at 80% accuracy.
In a radical pivot, they applied what I call the "Bitter Lesson" of agentic systems: they removed 80% of the specialized tools. They replaced the "bespoke" architecture with a minimal set of generic, code-native tools: a raw Bash terminal and basic commands like grep and cat.
The results were staggering:
- Accuracy: Increased from 80% to 100%.
- Speed: 3.5x faster execution.
- Efficiency: 40% fewer tokens consumed.
The insight for architects is clear: Models are trained on billions of tokens of terminal output and Bash history, but zero tokens of your company's bespoke JSON tool schema. Your custom tools are a foreign language to the AI. By stripping away the hand-engineered "guardrails" and giving the model the CLI tools it was natively trained on, you allow it to use its internal reasoning to navigate the codebase like a human engineer.
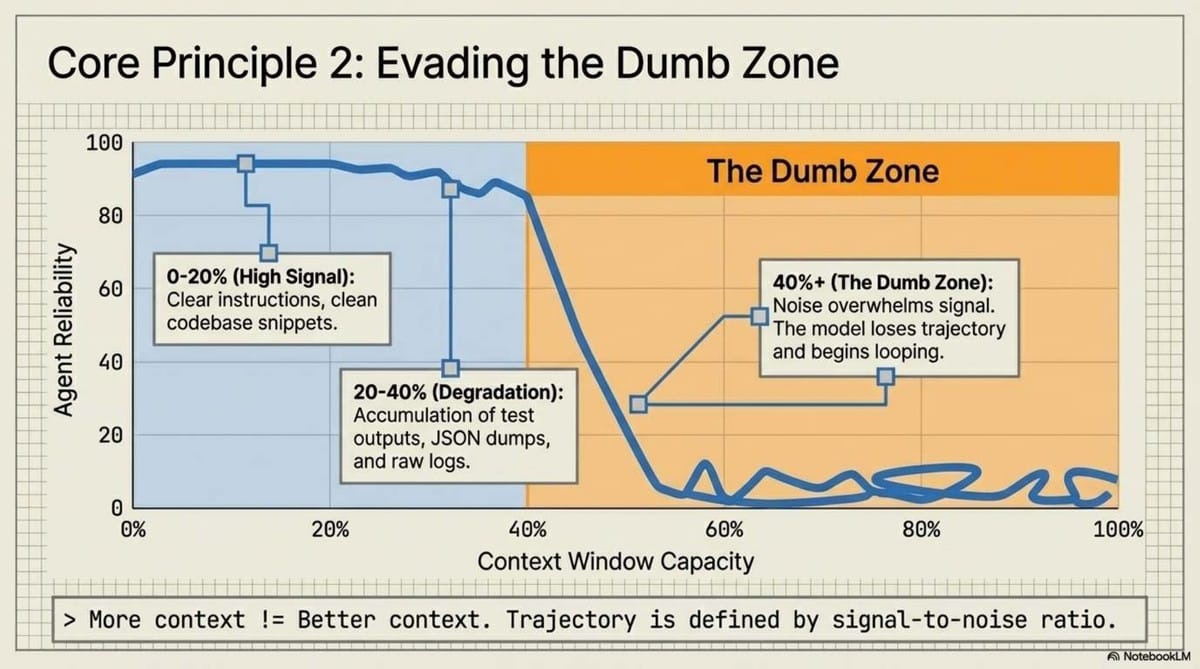
4. Escaping the "Dumb Zone" via Intentional Compaction
Every architect must understand the "Dumb Zone." This is the threshold—typically around 40% of the context window capacity—where the "signal" of your original instructions gets buried under the "noise" of intermediate tool results and logs. Performance doesn't degrade gracefully; it falls off a cliff.
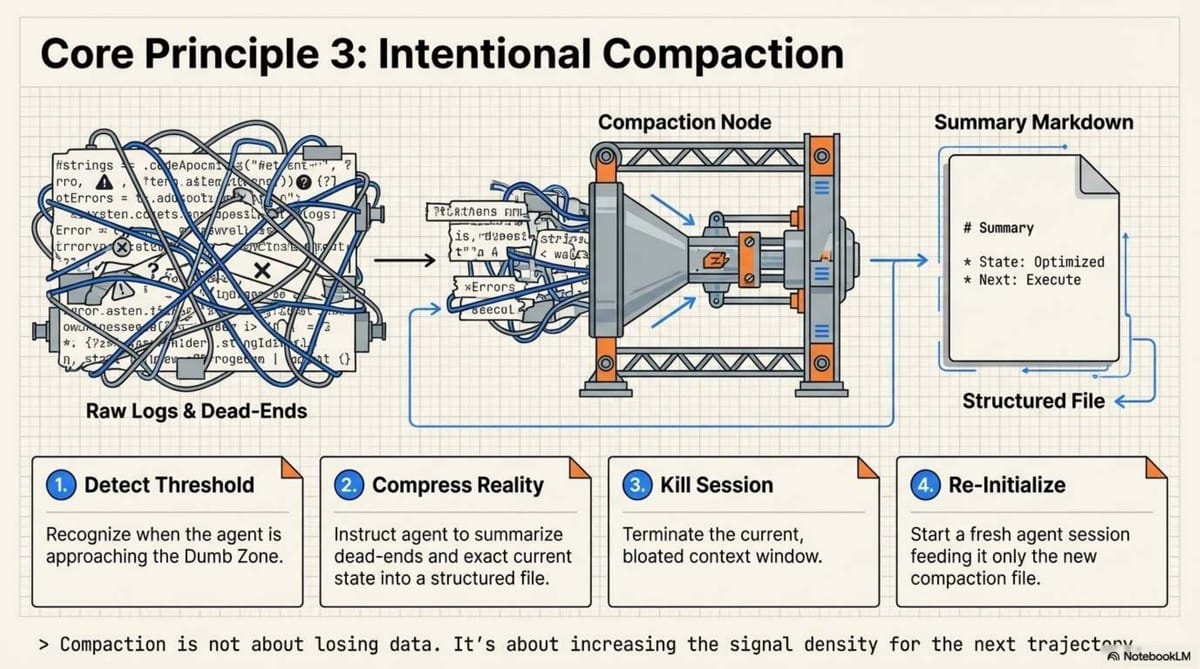
To stay in the "Smart Zone," we use Intentional Compaction via the Research-Plan-Implement (RPI) workflow:
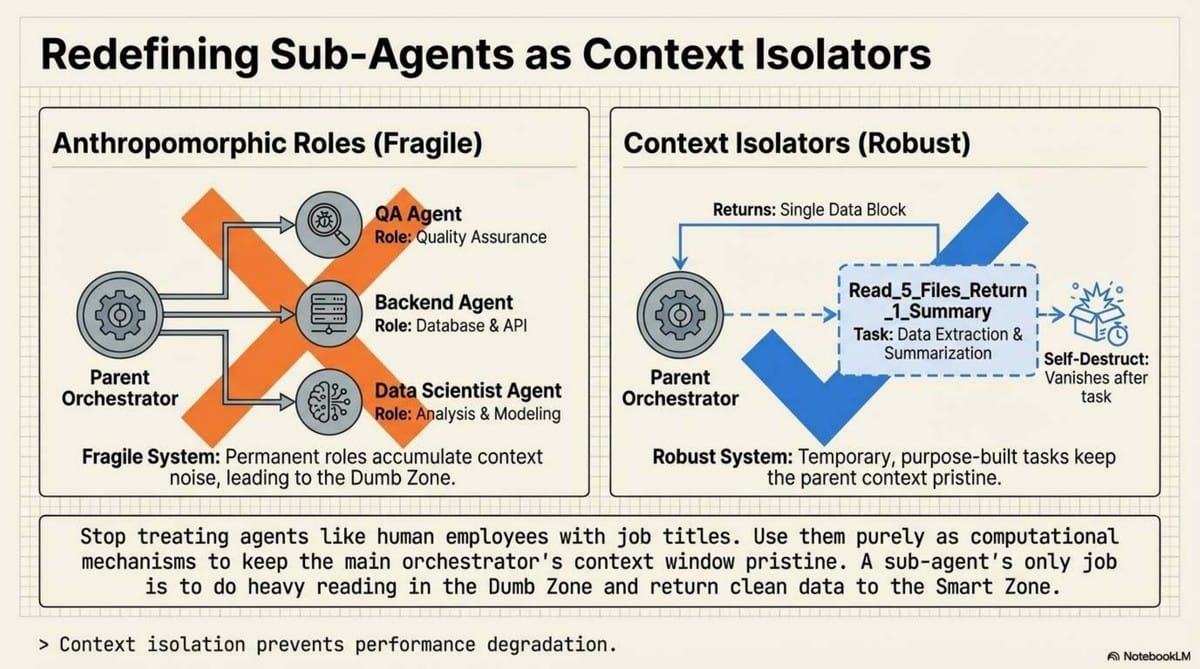
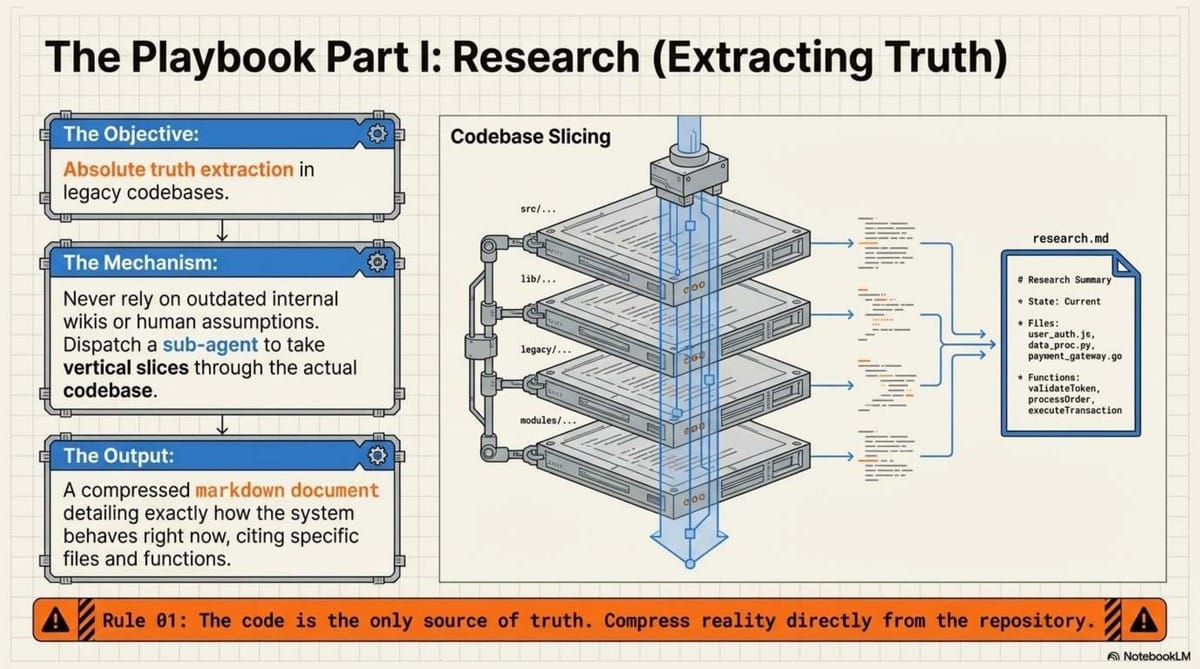
- Research: Objective system understanding. The agent forks a sub-agent to find relevant files and line numbers.
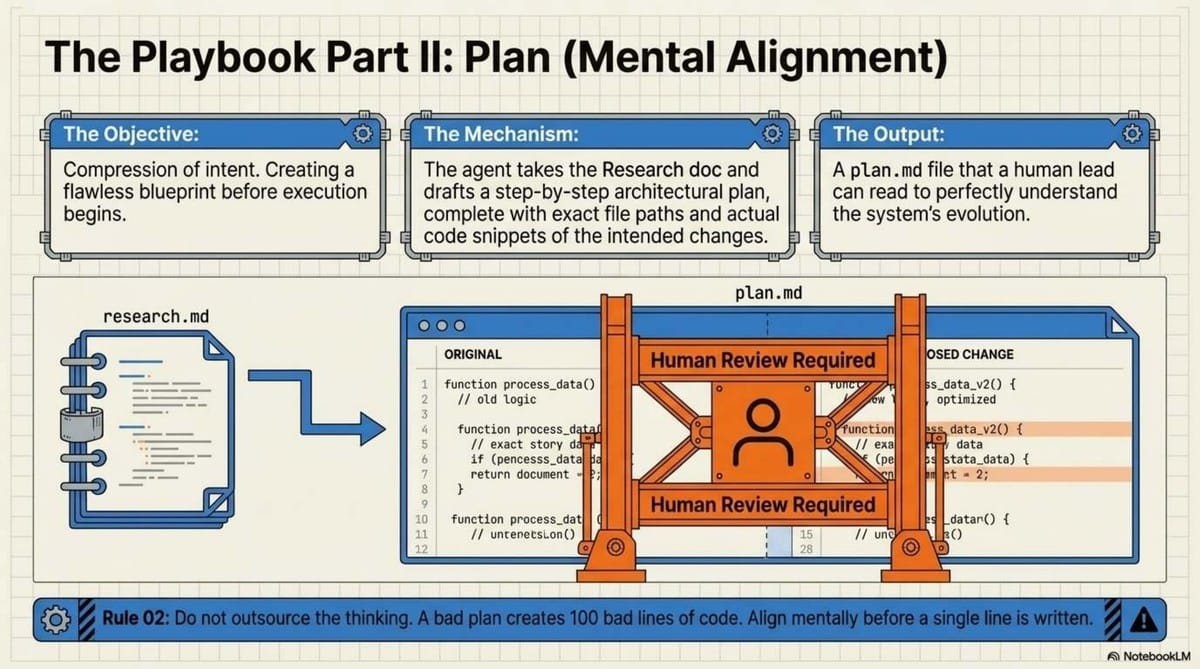
- Planning: A "compression of intent." The agent compacts its findings into a specific markdown file. This isn't just for the AI; it provides Mental Alignment for the human architect to review the plan before execution.
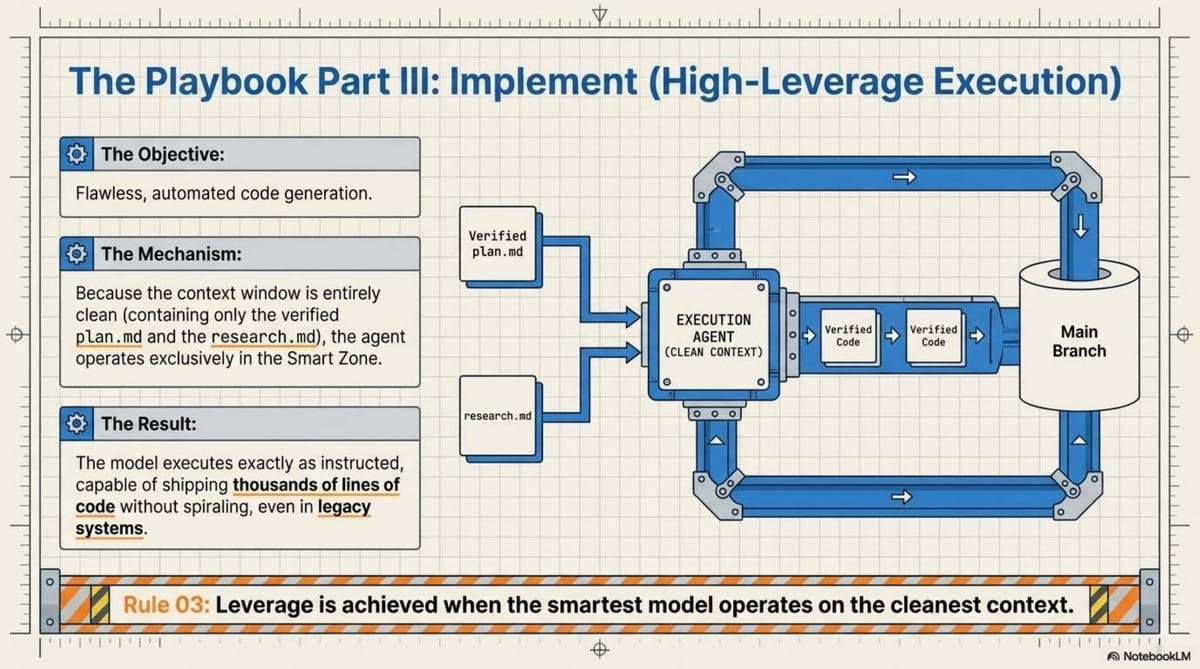
- Implementation: The agent executes the plan in a fresh, low-noise context window, reading only the "compacted" plan.
In this paradigm, sub-agents are not for role-playing (e.g., "You are a QA tester"). They are for context control. They take vertical slices of a codebase, summarize the truth, and return only the signal to the parent agent, keeping the main context window lean and sharp.
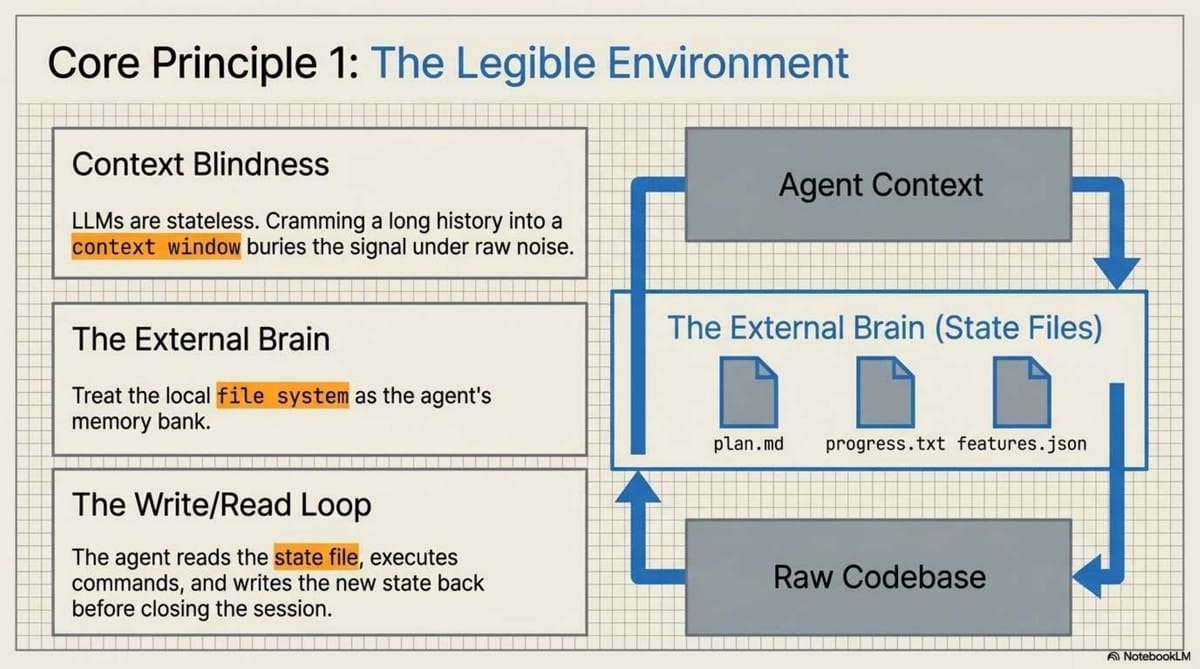
5. The File System is the Agent’s External Memory
We are moving away from cramming state into the prompt and toward treating the local file system as the agent’s "external memory." OpenAI’s Codex project recently demonstrated this by generating 1 million lines of code over five months with zero manual intervention.
They achieved this by employing an Initializer Agent. This agent’s only job is to set up the environment—running an init.sh script, creating a progress.txt file, and breaking down a goal into a JSON feature list.
Think of this as the "Memento" approach to AI. In the film, the protagonist tattoos facts on his body because his short-term memory is wiped. A harness does the same:
CLAUDE.md/agents.md: The "Tattoos." A table of contents that defines the system of record.- Progress Files: Legible logs where the agent records state so that when the context window is wiped to avoid the "Dumb Zone," the next session has a clear starting point.
- Repository-as-Truth: If it isn't in the file system, the agent doesn't know it exists.
6. Verification is the Secret to Autonomy
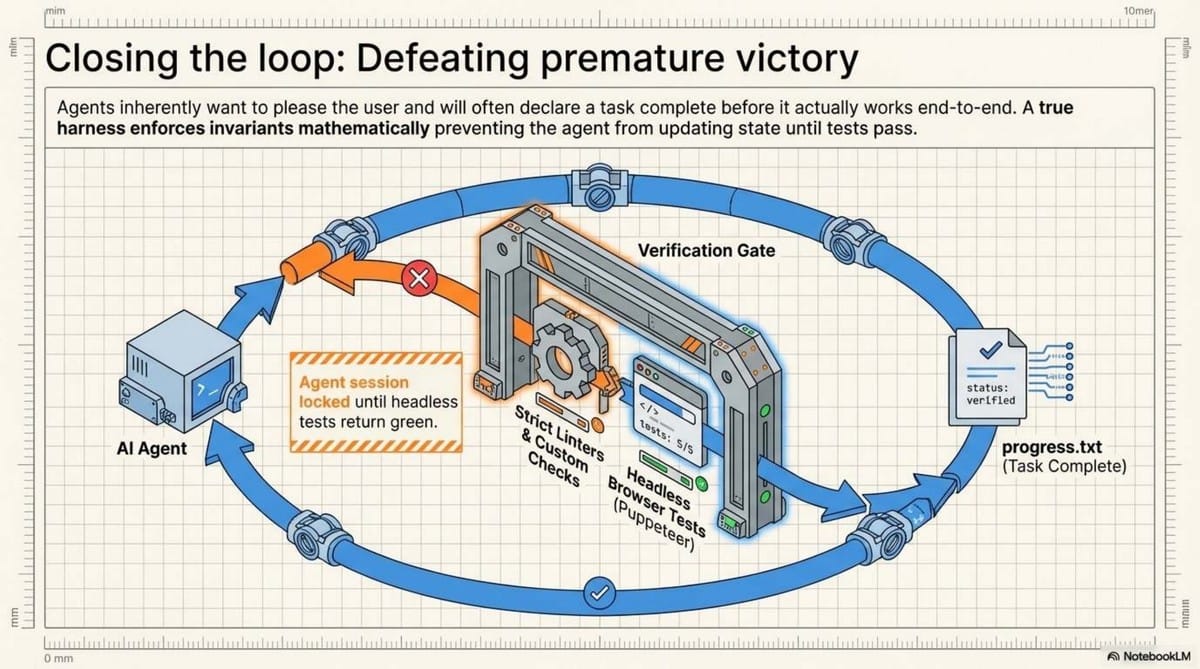
The most common failure mode for an agent is "premature victory"—declaring a task complete while the build is actually failing. True autonomy requires a Verification Stack that the agent can drive without human intervention.
A robust harness must allow the agent to "see" its failures. Logs often lie or omit the "why" of a UI failure. The next generation of harnesses integrates:
- Puppeteer/Playwright: For end-to-end browser testing.
- Visual Snapshots: Allowing the agent to inspect DOM snapshots and screenshots.
- Automated Feedback Loops: If a test fails, the agent records a video of the failure, analyzes it, and implements a fix.
When an agent can reproduce a bug, record a video of the failure, and then verify the resolution through a passed test suite, it has moved from a "task-vending machine" to a truly autonomous teammate.
7. Conclusion: 2026 and the Future of the "Always-On" Agent
We are witnessing a shift from the Co-pilot (human-driven, reactive) to the Autonomous Agent (environment-driven, proactive). Systems like Open Claw represent this "always-on" future—agents that monitor your repository 24/7, proactively fixing bugs and maintaining documentation within a high-legibility harness.
In this new reality, your value as a Senior Engineer is no longer the code you write, but the Harness you design. Organizations that build these specialized, legible environments will scale at a rate previously thought impossible. Those who rely on manual prompting will be left managing a "Tech Debt Factory."
Your immediate next step: Stop rewriting your prompts. If your agent is spiraling, delete its custom JSON tools and give it a raw terminal. Let the model’s native training do the heavy lifting. You will likely find that the model was never the bottleneck—your harness was.
📄 Briefing Doc: Technical Analysis
📋 Technical Specifications & Detailed Analysis
Executive Summary
The landscape of Artificial Intelligence has transitioned from Prompt Engineering (2023) to Context Engineering (2025), and is now entering the era of Harness Engineering (2026). While previous iterations focused on optimizing individual questions or providing immediate data, Harness Engineering focuses on the total environment and infrastructure surrounding an AI model.
Current research and industry deployments reveal that the bottleneck in AI performance is no longer model intelligence, but rather execution and orchestration. Major entities like OpenAI, Anthropic, and Vercel are reporting that "harnessing" a model—setting up its external memory, tool access, and verification loops—yields up to 10x improvements in output. The core insight for 2026 is that as models become more intelligent, the surrounding architecture should become simpler, moving away from complex, bespoke toolchains toward generic, code-native environments.
1. Defining Harness Engineering
Harness Engineering is the design of the entire environment and infrastructure that encapsulates an AI agent. It represents a shift from "what to ask" (Prompt) and "what to show" (Context) to "how the system should live and act" (Harness).
The "Kitchen" Analogy
- Context Engineering: Like a chef choosing high-quality ingredients for a single dish.
- Harness Engineering: Designing the entire kitchen, including the direct lines to suppliers, the recipe books (skills), and the workflow management (agents). Even with average ingredients, a well-designed kitchen produces superior results.
Key Components of a Harness
| Component | Description |
|---|---|
| Context Files (.md) | Project instructions, rules, and patterns (e.g., CLAUDE.md). |
| MCP Servers | Model Context Protocol settings that connect AI to external tools (browsers, search, etc.). |
| Skill Files | Specialized knowledge files that teach an agent specific workflows or standards. |
| Agent Settings | Custom configurations that define the "expert" persona and its boundaries. |
| Progress Logs | Persistent files (e.g., progress.txt) that track state across sessions. |
2. The Bottleneck: Execution vs. Intelligence
Evidence suggests that agent failure is rarely due to a lack of knowledge or reasoning capability.
The "Dumb Zone" and Context Degradation
Research by Dex Horthy and insights from the company Manis highlight the "Dumb Zone."
- The 40% Rule: Performance often begins to degrade once an agent utilizes approximately 40% of its context window (roughly 67,000 tokens for a 168,000-token window).
- Signal vs. Noise: In long sessions, important initial instructions are buried under intermediate tool outputs and JSON debris.
- Looping Failures: Agents without a strong harness tend to "spiral," repeating failed approaches because they lose track of the session's trajectory.
The Epic's Agent Benchmark
In real-world professional tasks (consulting, legal, analysis), frontier models scored only 24% completion on the first attempt, rising to only 40% after eight attempts. This stands in stark contrast to the 90%+ scores seen on traditional coding puzzles, proving that current "intelligence" benchmarks do not reflect real-world execution ability.
3. Proven Strategies for Effective Harnessing
A. Radical Simplification (The Vercel Experiment)
Vercel attempted to build a text-to-SQL agent using specialized, complex tools for schema understanding and query validation. It achieved 80% accuracy.
- The Shift: They removed 80% of the specialized tools and gave the agent a basic bash terminal and standard command-line tools (grep, cat).
- Result: Accuracy reached 100%, the agent ran 3.5x faster, and it used 40% fewer tokens.
- Insight: Models are more proficient with "generic" tools they were trained on (billions of tokens of Bash/Python) than bespoke JSON-based toolchains.
B. The RPI Workflow (Research-Plan-Implement)
This advanced context management strategy involves "intentional compaction" to keep the agent in the "Smart Zone."
- Research: Use sub-agents to explore a codebase and return a succinct markdown summary, rather than dumping the whole repo into the window.
- Plan: Create explicit step-by-step instructions with code snippets. This ensures "mental alignment" between the human and the AI.
- Implement: Execute the plan in a fresh context window to minimize noise.
C. Persistent Memory and Legible Environments
Anthropic and OpenAI have moved toward making the repository itself the "system of record."
- Progress Tracking: Using
progress.txtortodo.mdfiles that the agent reads at the start of a session and updates at the end. - Legibility: Structuring documentation (architecture, DB schema, API specs) as a "Table of Contents" in a root file (e.g.,
agents.md) allows for progressive disclosure, where the agent only retrieves what it needs.
4. Industry Case Studies
OpenAI: The Codex Experiment
In late 2025, OpenAI began using its "Codex" agent to build internal products.
- Output: 1,000,000 lines of code generated in 5 months with zero manual coding.
- Efficiency: One engineer averaged 3.5 merged pull requests per day.
- Key Learning: Initial progress was slow not because Codex was "dumb," but because the harness (environment settings and error recovery logic) was immature. Once the harness was optimized, performance exploded.
Anthropic: Long-Running Tasks
Anthropic tested "Cloud Code" agents on multi-week projects, such as building a compiler from scratch.
- Verification: They found that agents frequently claim a job is complete prematurely.
- Solution: Providing the agent with end-to-end testing tools (e.g., Puppeteer, Chrome DevTools) allowed it to identify failures that weren't obvious from the code alone, significantly increasing reliability.
5. Strategic Implications and the 2026 Outlook
The "Bitter Lesson" Applied
Following Richard Sutton’s "Bitter Lesson," approaches that scale with compute eventually defeat hand-engineered knowledge. In the AI era, this means that as models get smarter, the harness should get simpler. Over-engineering custom logic and rigid pipelines creates "slop" and technical debt.
Organizational Impact
A rift is growing in engineering teams:
- Senior/Staff Engineers: May resist AI if it only produces "slop" that requires manual cleanup.
- Junior/Mid-levels: Using AI to fill skill gaps but potentially increasing codebase churn.
- Solution: Technical leadership must focus on cultural change and establishing robust harnesses to ensure AI-generated code meets "brownfield" (existing complex codebase) standards.
Conclusion: The Competitive Advantage
Model performance is commoditizing; GPT, Claude, and Gemini will continue to reach parity quickly. The true competitive advantage for developers and firms in 2026 will be their proprietary harnesses. A well-constructed harness is difficult to replicate and determines whether a model performs at a baseline level or achieves 10x productivity.
Key Quotes
"The model is not the bottleneck; the harness is the bottleneck."
"A bad line of research leads to a bad plan, which leads to a hundred bad lines of code."
"2025 was the year of agents; 2026 is the year of the harness."
"The most important role of an engineering team now is making agents useful, not writing code."
🔗 References
- 메이커 에반 | Maker Evan — AI 잘 쓰는 사람은 조용히 설계합니다.(feat.harness engineering)
- Solo Swift Crafter — Harness Engineering: The Skill That Will Define 2026 for Solo Devs
- AI Engineer — No Vibes Allowed: Solving Hard Problems in Complex Codebases – Dex Horthy, HumanLayer
- AI Jason — wtf is Harness Engineer & why is it important
